Semi-Supervised Learning: A brief perspective on some recent methods
Semi-supervised learning aims to learn from limited data by using both limited labelled data and unlabelled data efficiently to improve the learning objective. In this blog post I will give some introduction on recent popular methods such as Mean-Teacher (MT) [1] and Virtual Adversarial Training (VAT) [2] and finally draw some conclusions on what some of these popular methods are actually trying to do. These methods have achieved some impressive results - CIFAR-10 dataset has 50000 train images, VAT uses only 4000 images to reach 90% accuracy. FixMatch [3] further reduces this by a factor of 100 by only using 40 images to achieve the same score, impressive!
Many semi-supervised methods can be seen as doing some form of label propagation. That is assign the same label to data points that are close together. The way these methods achieve this may seem different, but in essence they can be seen as doing some kind of consistency regularization.
To motivate this further, we know deep networks can produce sharp decision boundaries. Having only a few training examples makes this even worse as they are prone to overfitting. Hence we need a way of training the deep networks to make them have smoother decision boundaries. The Mean-Teacher [1] paper has a nice example illustrating this.
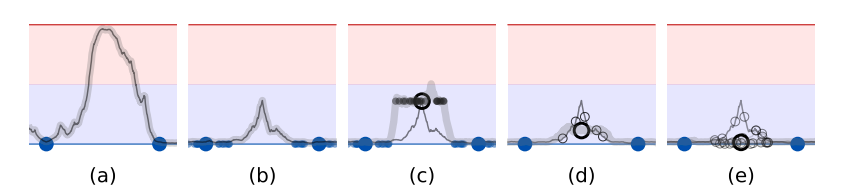 Assume Fig (a) is the decision boundary of a regression problem, with the two blue dots as the outputs of labelled data points. In the absence of
regularization, we can see the decision boundary having a sharp increase in its outputs between these labelled points which might not be desirable.
Assume Fig (a) is the decision boundary of a regression problem, with the two blue dots as the outputs of labelled data points. In the absence of
regularization, we can see the decision boundary having a sharp increase in its outputs between these labelled points which might not be desirable.
Now adding some regularization like dropout or input perturbation will make sure the region around a labelled data point behaves consistently as shown in Fib (b). Here the smaller blue dots represent the outputs of the perturbed data points.
These two figures explain concepts that we are already familiar with and use to train our deep learning models. The question now is in a limited label setting how do we further use unlabelled data points to achieve something similar? Mean-Teacher tries to achieve this by using two different networks: a teacher network and a student network as shown in the figure below.
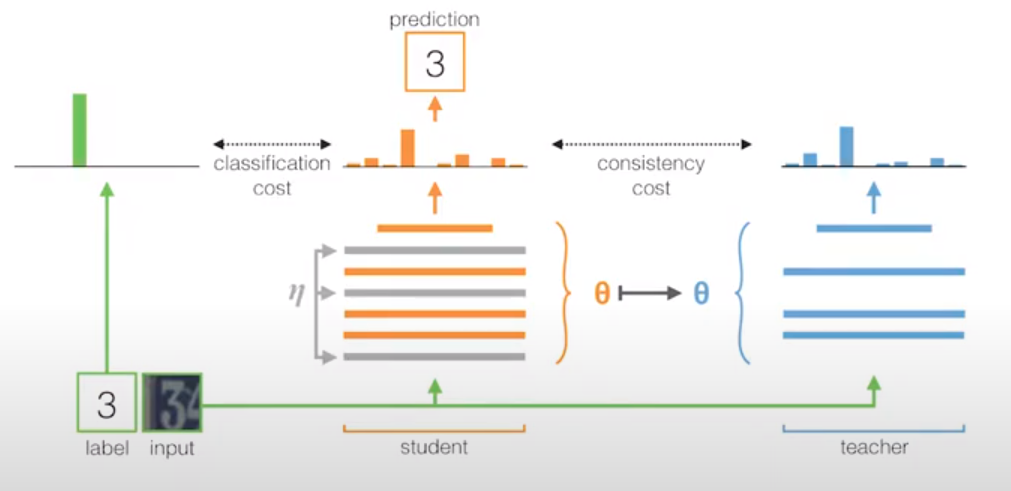
Both the teacher and the student networks share the same parameters. The student network outputs are perturbed using noise $\eta$ (similar to Ladder Networks [4]). The student network can be trained using the cross-entropy objective in the case of a classification setting which achieves similar outcomes as illustrated in Fig (b). And for the unlabelled data, we can force the student to produce the same output as the teacher using a consistency regularization term $ \mathcal{L}_{\text{CST}} $. This way the neighbourhood around an unlabelled data point shown as a black circle in Fig (c) remains consistent with the teacher’s output.
The consistency regularization term can take many forms such as the KL divergence
$ L_{\text{CST}} = \text{D}_{\text{KL}}[p^t | p^s]$
where $p^t$ is the output of the teacher and $p^s$ that of the student.
If teacher’s target is wrongly predicted (black circle at the peak in Fig (c)), the noisy student is forced to have the same target, which creates the flat surface in Fig (c), whereas the desired output should have the same y axis value as the blue dots. To deal with this we can make the teacher model also exactly identical to the student model by adding noise $\eta$. We can take the average of the outputs in the presence of noise to avoid getting stuck at a peak as shown in Fig (d). We can draw parallels to bagging where multiple learners reduce the variance by aggregating their outputs. In the same spirit, we could perhaps have multiple teacher models instead of just one noisy teacher model.
We can make an observation here - since the student and teacher are exactly the same, we can redefine this setting with only a student network. The student network should simply be consistent with itself across various noisy perturbations.
We can obtain an effect similar to using multiple teacher models by using exponentially moving average (EMA) of the prediction of a data point between last epoch and current epoch and using this as a target of the teacher for the student network. This can be seen as something similar to taking an average between many different teacher networks. This is known as Temporal Ensembling. The drawback here is that we have to wait an epoch before seeing the same example again.
Instead of doing EMA on targets of the same example across epochs, we can instead perform EMA on the weights of the network across updates. This is the Mean Teacher model and hopes to achieve an effect similar to Fig (e).
Virtual Adversarial Training (VAT) is another such consistency regularization method. The main difference with Mean-Teacher is that Mean-Teacher tries to make the output distribution around an input data point isotropically smooth by randomly perturbing the input. VAT instead smooths the output distribution by selecting the most anisotropic direction around the input (adversarial example). This means we can find the adversarial direction on the input $x$ that makes the output diverge the most and make the model to produce consistent outputs.
$ L_{\text{CST}} = \text{D}_{\text{KL}} [p(y|x) | p(y|x + r_a)] $
where $r_a$ is the adversarial direction:
$ r_a = \arg \max_{r; ||r || < \epsilon} \text{D}_{\text{KL}} [p(y|x) | p(y|x + r)]$
Here $x$ can be either labelled and unlabelled. Replacing $r_a$ with a random direction $r$ we can draw parallels to the Mean-Teacher model’s random perturbation.
Another way of approaching this problem is to minimize entropy to perform self training. Here we try to make the current prediction of the model as its own label and minimize entropy $H(x)$ to make the model more confident of its predictions.
$ H(x) = - \sum_i p(x) \log p(x)$
By making the model more confident on a data point, this could further push the decision boundary away from the data point. Entropy Minimization along with a regularization term to keep the decision boundary smooth can yield good results. This idea has been further discussed in “Learning from Limited and Imperfect Data” CVPR 2021 workshop and can be viewed here.
References:
[1] Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.
[3] Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning.
[4] FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence.
[5] Semi-Supervised Learning with Ladder Networks.